
What is catastrophic forgetting?
Modern software utilizes increasingly advanced deep learning techniques to perform tasks that seemed impossible for machines only a few years prior. In some areas, however, artificial neural networks still have a long way to go before they can compete with the human brain, especially when it comes to lifelong learning. The reason for this lies in the way these algorithms operate.
Training a machine learning engine involves so-called weights. Simply put, when a machine learning model receives an input, a weight is applied to approximate a certain desired output. For example, if you input a dog’s photo, you want your model to categorize it as a dog. If it outputs “cat” instead, the weights have to be adjusted.

Now imagine that you’ve successfully trained your model on dog pictures, which it recognizes 99% of the time. Then, you start another training session, this time for bird pictures. The model readjusts its weights to recognize birds – and thereby loses its ability to identify dogs. This effect is called catastrophic forgetting or catastrophic interference.
How to prevent catastrophic forgetting
Several solutions have been proposed to mitigate the effects of this phenomenon. After all, training a machine learning model for a specific task takes a lot of time, so losing progress is highly inefficient.
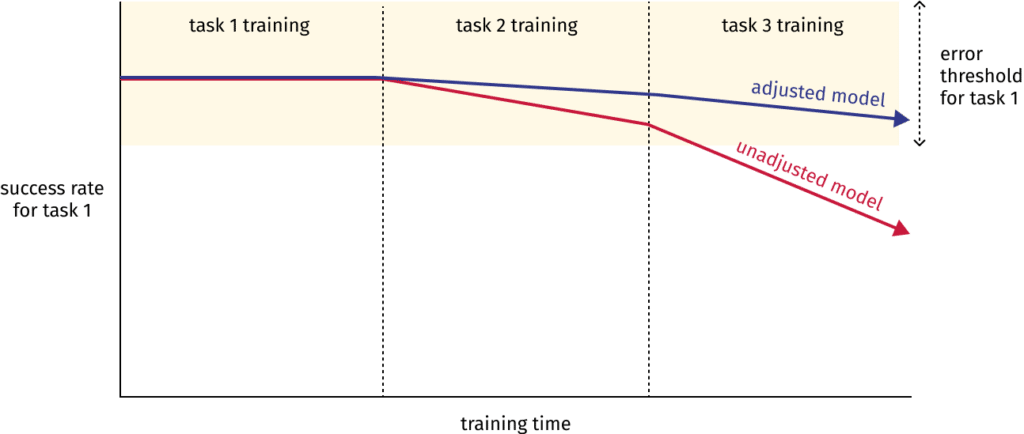
One way to minimize catastrophic forgetting is to ensure that when weights fine-tuned for task 1 are trained for task 2, they stay within a certain error threshold for task 1. This is called Elastic Weight Consolidation, where “elastic” means that changes in the weights are constrained more strongly the farther they drift from their previous state. Additionally, the weights most critical for good performance in task 1 are restricted more than less important ones.
Another approach mimics the different functions of the human brain’s hippocampus and neocortex. Generally speaking, episodic memories are stored in the hippocampus, whereas the neocortex stores more general information. When certain memories are relevant in a broader sense, this information is transferred from the hippocampus to the neocortex.
In Bi-level Continual Learning, inputs are accordingly divided up between two models representing the hippocampus and the neocortex. The former bases its weight allocations on the latter and returns insights for future training. The goal is to combine a vast repository of general knowledge with the ability to quickly learn new tasks, just like humans do.
How Scanbot’s engine works
Our own machine learning engine needs to recognize many different types of documents in order to reliably extract information from them. This makes minimizing the effects of catastrophic forgetting a priority.
Our approach is modularization: Instead of letting our engine handle all of the tasks involved in recognizing and extracting document data by itself, we divide the tasks between several smaller modules. This means that modules can be trained individually to optimize their performance without affecting the others.
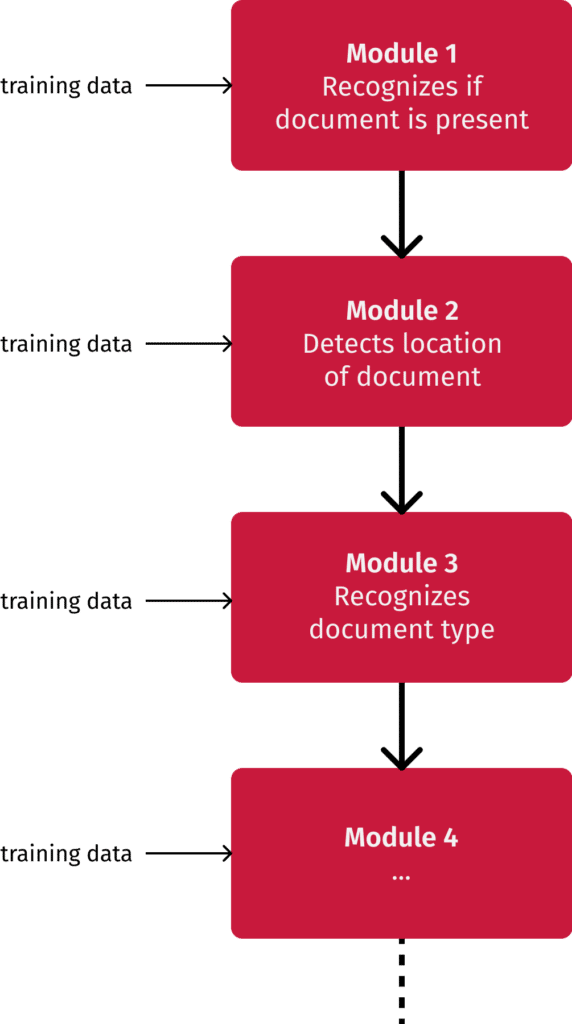
Previously, we worked on a single large model, but there were clear drawbacks. For one, training took up to 8 hours per task. For another, training this engine on different document types – which nonetheless share many similarities – sometimes led to mix-ups during the recognition phase. The modularization approach alleviates these problems, with a single module training session now only taking 15 to 120 minutes and less potential for confusion.
Our goal is to add a new document type to our machine learning engine within just 3 business days. Currently, this takes between 2 and 3 weeks. Our developers are working hard to make this a reality, so that our computer vision algorithms support all types of documents you may need to process for your use case. If you would like to learn more about Scanbot’s Data Capture SDK, don’t hesitate to get in touch with our solution experts. If you need to automate complex document processing, we will gladly train our models for the required data extraction. Let’s talk.