Document Scanner SDK using on-device intelligence
Turn mobile devices into flatbed scanners
Trusted by
300+
global
industry leaders
High-quality scans
Let your users generate high-quality scans suitable for automated processing.
Simple to use for anyone
Allow even non-tech-savvy users to easily create crisp document scans thanks to user guidance, automatic capture, auto-cropping, and other features.
On-device intelligence
100% offline – no servers, no tracking, complete data security.
Available for App & Web
The SDK supports iOS, Android, Web, Windows, Linux, and all common cross-platform frameworks, including Flutter, React Native, and .NET MAUI.
Customizable UI components
Our Ready-To-Use UI components cover all document scanning scenarios and are highly customizable.
Learn more about our document scanning features
The SDK offers a comprehensive set of features designed to simplify the scanning experience for your users and improve output quality.
-
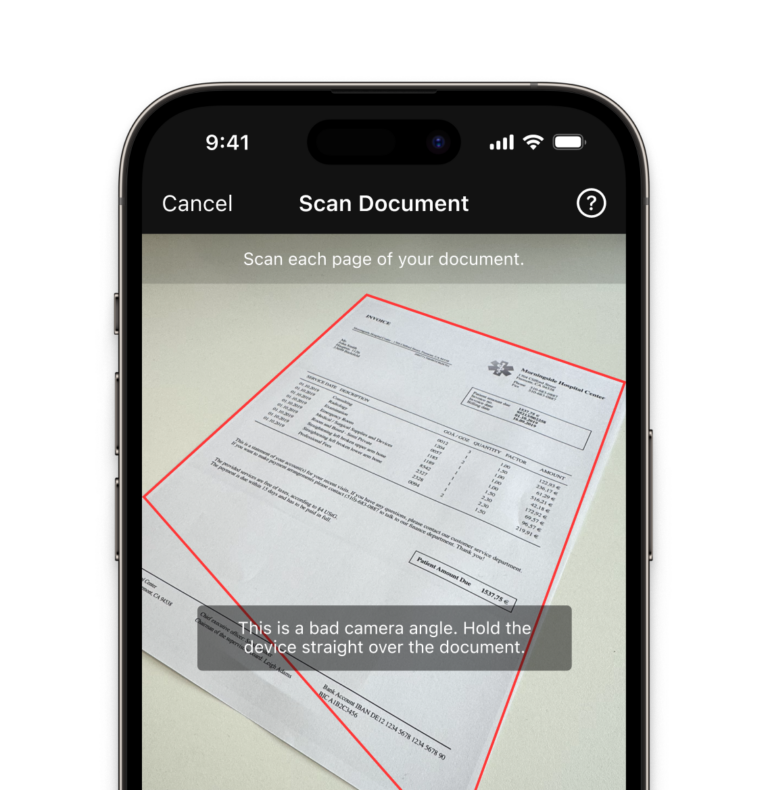
User guidance
Ease of use is crucial for any app’s design, but especially if the user base is large. Our on-screen user guidance helps even non-tech-savvy users create the perfect scan.
-
Automatic capture
-
Automatic cropping
-
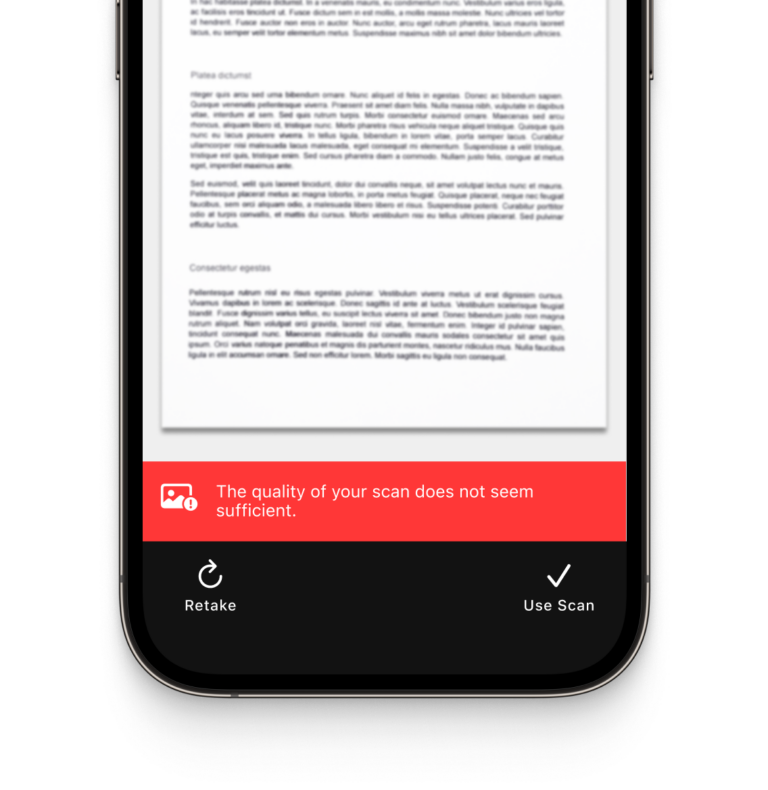
Document Quality Analyzer
-
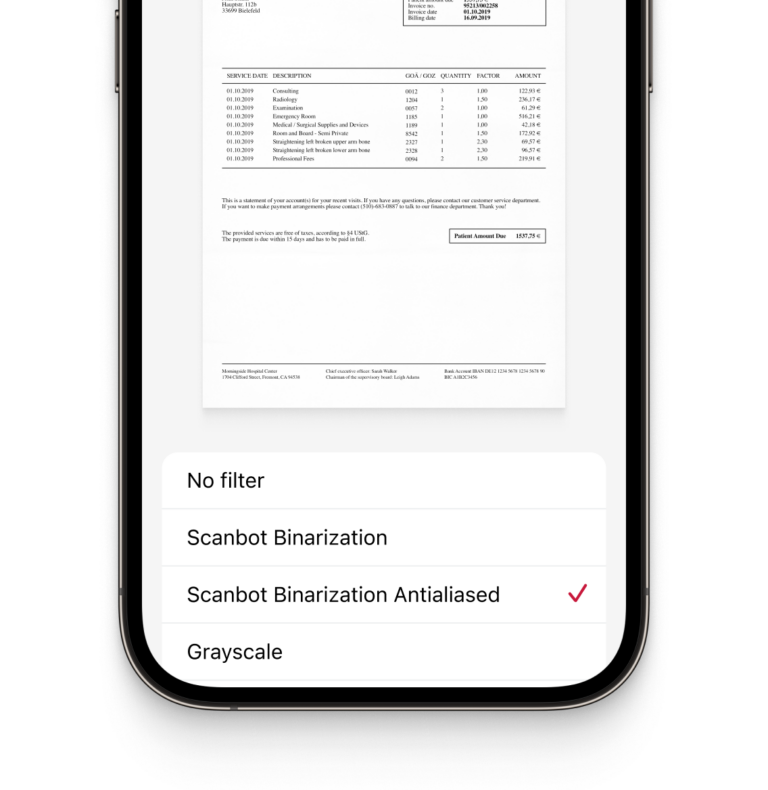
Custom filters
-
Multiple export formats



Why Scanbot SDK?
Fixed pricing
Unpredictable costs are frustrating. The Scanbot SDK comes with a flat annual fee that includes everything, without limits on users or scans.
On-device intelligence
Our SDK works entirely offline, without any server connections or usage tracking. This ensures complete data security.
Enterprise support
Directly connect with your dedicated Customer Success Manager and our support engineers via Slack or Teams.
Frequently Asked Questions
What is a document scanner SDK?
A document scanner software development kit (SDK) is a set of development tools that turns any portable device, such as a smartphone or tablet, into a reliable and easy-to-use document scanner. The Scanbot Document Scanner SDK utilizes machine learning and computer vision technology to deliver fast and accurate scanning results.
It enables users to generate high-quality scans suitable for automated processing and offers advanced features like automatic capture and cropping, user guidance, and custom filters. The Scanbot Document Scanner SDK operates entirely offline and can be integrated into a mobile app or website within hours.
Why should I use document scanning software?
A software-based document scanner is installed on devices that are already available in most cases, such as smartphones or tablets. This means that you don’t have to invest capital in additional hardware. Furthermore, it enables faster scanning than with traditional hardware devices such as printers and delivers higher-quality scans. Consequently, data can easily be extracted and used as input for the backend system.
What should I consider when choosing document scanning software?
Overall, the scanning software should provide high-quality outputs that can be used as input for backend systems. Moreover, it should have a user-friendly and accessible interface.
Some important factors to consider are:
Performance and quality: Ensure that the software generates crisp scans in all conditions, even with bad lighting or damaged documents.
Compatibility: Look out for a solution that is compatible with your development platform and the devices you want to support.
Features: Depending on your use case, some advanced features might be valuable to have in your document scanning software. For example, Scanbot’s Document Scanner SDK offers custom filters that transform document images into optimal input for your backend systems. They include grayscale, several binarization options, and more.
Developer support: Make sure your software provider offers developer support and maintenance for a smooth integration process. Scanbot SDK provides extensive documentation as well as dedicated Slack and Teams channels for direct customer support.
Pricing model: Choose a pricing model that allows you to scale your use case without having to worry about increasing costs. To not limit your usage, we offer unlimited scanning for a fixed annual price.
Where can I buy a document scanning software?
There is a lot of open-source document scanning software available. However, scanning results are often of poor quality, resulting in unreliable data extraction that is useless for your backend. Moreover, developer support is an important missing factor with open-source software.
Consider paid scanning software when quality and support are important to you. Scanbot SDK provides extensive documentation as well as dedicated Slack and Teams channels for direct customer support.
To learn more about our solution, try our demo app or request your trial license.
How do I integrate the Scanbot Document Scanner SDK into my app?
Our Document Scanner SDK comes with detailed documentation that takes you through the integration process step by step. The entire integration doesn’t take longer than a few hours. If you need any additional support, we are happy to help you with our free support channels.
Which platforms is the Scanbot Document Scanner SDK currently available for?
The SDK supports development for iOS, Android, Web, and all common cross-platform frameworks, including Flutter, React Native, and .NET MAUI. You can try the Scanbot Document Scanner SDK by downloading the demo app or requesting a free trial license.