
What is OCR?
The digitization of paper-based documents holds enormous potential for businesses to improve efficiency. Once converted into ones and zeros, software can search through the data, sort it, and analyze it to deduce valuable insights. The process of optical character recognition (OCR) is where that transformation happens.
Although the term OCR is widely known, the technology itself is a black box for most. Before diving deeper into the technical details, it’s worth noting which subcategories of OCR exist and how they differ from each other. These four approaches fall under the umbrella term OCR:
- Optical character recognition (OCR proper): Single typewritten characters
- Optical word recognition (OWR): Whole typewritten words
- Intelligent character recognition (ICR): Single typewritten or handwritten characters, utilizes machine learning
- Intelligent word recognition (IWR): Whole typewritten or handwritten words, utilizes machine learning
Depending on your use case, you may need different types of software, with or without machine learning capabilities. There’s also the difference between document text and scene text. Scene text consists of letters and words “in the wild”, for example, on a street sign. These are generally much harder to process, since things like angle, contrast, and font variations have to be factored in. It’s thus best to ask yourself beforehand what texts you will perform data extraction on, so you can choose an appropriate software solution.

OCR preprocessing
Before the software begins scanning a document for characters or words, the input image will need some preparation. By optimizing the source image, you can achieve better end results. Two of the most important adjustments concern angle and contrast.
First off, even if captured with a flatbed scanner, scanned paper documents are often skewed at a slight angle. Correcting this makes it easier for the OCR software to establish text baselines. In turn, this allows it to better understand where one word ends and another word begins.
The next step is binarization. This means that a color or grayscale document is reduced to black and white to maximize the contrast between the text and the background. Depending on the quality of the input, it may not be possible to eliminate the background completely, resulting in a grainy image that interferes with recognition. To avoid this, image filters can be applied before binarization.
Text output and postprocessing
After capturing the entire document, the OCR software needs to output the text in a useful digital format. There are several options for this. The simplest way is a plain text file with all information in one block of text, without any line breaks or layout. This may be viable for very short texts, but less so for larger documents or complex forms.
Some tools offer to generate a Word file that mimics the formatting of the input document. However, the result is often less than perfect and may be hard to edit.
Another option is to overlay the recognized text as an invisible layer on top of a PDF file of the input image. This maintains the look of the original, but text can still be highlighted and searched for in the file using just a PDF viewer.
How machine learning can be used to improve OCR capabilities
The purpose of extracting data from a document with OCR is often to avoid manual data entry in favor of automatic processing. By augmenting the process with deep learning technology, you can achieve more accurate results.
If, for example, you would like to extract text from invoices automatically, you know that they all contain certain types of information, but not where they are on the respective document. A machine learning model can be trained to recognize data types like addresses and account numbers and label them accordingly for automated data extraction as key-value pairs, which can then be used for further data processing.
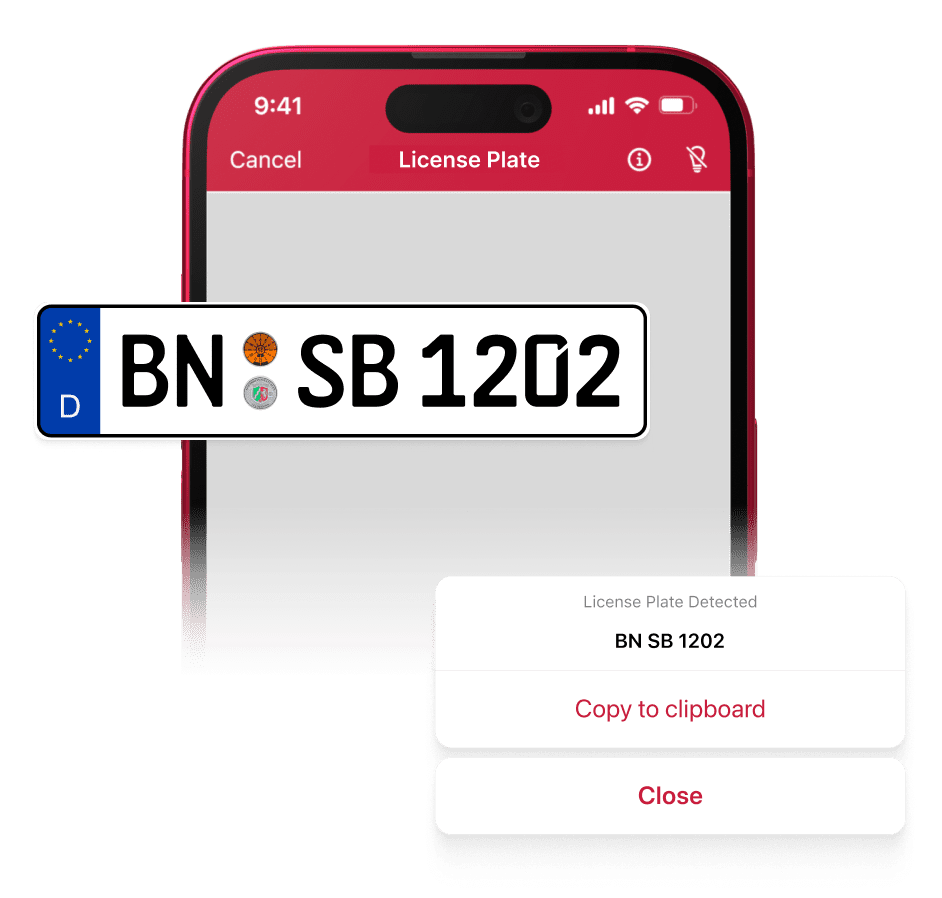
Deep-learning-assisted OCR is also crucial for scene text recognition. For instance, you might like to automatically register vehicles entering your company premises using a license plate scanner. In this case, OCR technology alone is not enough. Instead, you will need a trained model that first recognizes and captures the license plate, then applies filters and other adjustments to the image for better processing, reads out the characters on the plate, and finally saves them in a machine-readable format.
Implementing OCR to optimize business process
Many companies are trying to reduce the amount of paper documents going around. One strategy is to scan every paper document coming in, file it electronically in a document management system, so everyone who needs it has access to it, and then immediately archive the paper version for good.
This strategy can be improved further by applying OCR to all scanned documents. This way, even when someone is looking for a specific document years later, they can do a full-text search for keywords like company names, dates, addresses, and more. This drastically reduces the time employees spend looking for documents.
If your business has a very particular use case for automatic document processing, you are in luck: The more specific your requirements are, the easier it is to train an OCR engine using deep learning on them, resulting in excellent output. While the prospect of training a machine learning model may sound intimidating at first, the long-term results are more than worth the effort.
Scanbot SDK’s Document Scanner uses the Tesseract OCR engine to recognize and digitize text while applying different image filters to optimize results. Our Data Capture SDK goes one step further: Leveraging our deep learning model, it can recognize all kinds of document and scene text. We are currently fine-tuning our engine so that it can be successfully trained on a new document type within just three business days.
If you think that this technology fits the bill for your use case, feel free to get in touch with our solution experts. They will gladly help you integrate OCR into your business processes.