
Was ist catastrophic interference?
Dank hochentwickelter Deep-Learning-Technologie verfügt maschinelle Intelligenz heutzutage über Fähigkeiten, die wenige Jahre zuvor kaum vorstellbar waren. In einigen Bereichen hinken die künstlichen neuronalen Netze dem menschlichen Gehirn jedoch deutlich hinterher, so etwa beim lebenslangen Lernen. Der Grund dafür liegt in der Funktionsweise der Algorithmen.
Beim Training einer Machine-Learning-Engine kommen sogenannte Gewichte (weights) ins Spiel: Erhält das Modell einen Input, wendet es dieses Gewichte an, um einen Output zu generieren, der einem bestimmten Wunschergebnis möglichst nahekommt. Speisen Sie beispielsweise ein Foto von einem Hund ein, möchten Sie, dass dieses auch als Hundefoto kategorisiert wird. Erkennt das Modell stattdessen eine Katze, müssen die Gewichte angepasst werden.

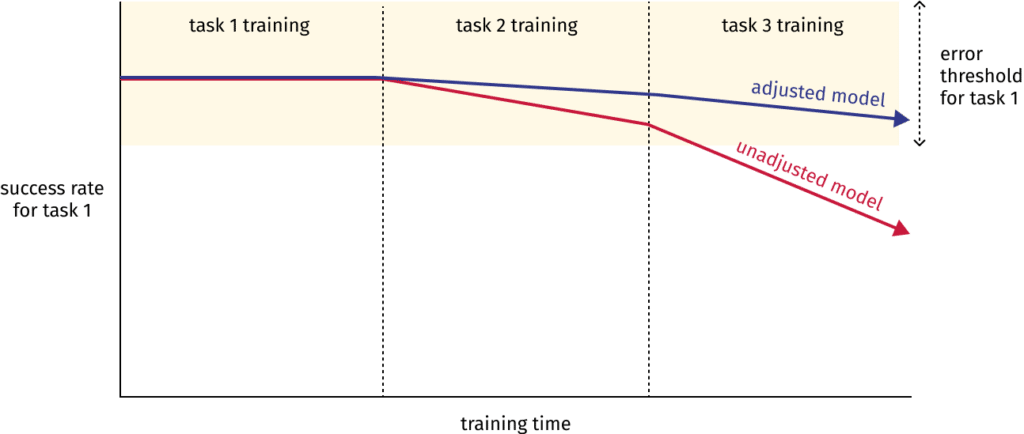
Nehmen wir an, dass Sie ihre Engine erfolgreich auf Hundefotos trainiert haben und sie eine Trefferquote von 99% vorweisen kann. Nun starten Sie eine neue Trainingseinheit, diesmal mit Fotos von Vögeln. Die Gewichte werden entsprechend angepasst – und damit geht die Fähigkeit zum Erkennen von Hunden verloren. Dieser Effekt nennt sich “katastrophale Interferenz”, oder üblicher auf Englisch catastrophic interference bzw. catastrophic forgetting.
Wie kann catastrophic interference vermieden werden?
Mit dem Training von Deep-Learning-Modellen geht ein großer Zeitaufwand einher. Daher wurden verschiedene Lösungsansätze entwickelt, um die Auswirkungen dieses Phänomens zu begrenzen.
Einer dieser Ansätze ist Elastic Weight Consolidation. Dabei wird sichergestellt, dass diejenigen Gewichte, die für Aufgabe 1 relevant sind, beim Training für Aufgabe 2 nur insoweit verändert werden, dass eine gewissen Fehlerquote für Aufgabe 1 nicht überschritten wird. Da es sich um “elastische” Anpassungen handelt, werden Änderungen an den Gewichten umso stärker eingeschränkt, je wichtiger sie für eine erfolgreiche Bewältigung der ersten Aufgabe sind.
Ein anderer Ansatz orientiert sich an den unterschiedlichen Funktionen des Hippocampus und des Neocortex im menschlichen Gehirn: Grob zusammengefasst speichert der Hippocampus episodische Erinnerungen, wohingegen im Neocortex allgemeine Erkenntnisse abgelegt werden. Haben bestimmte Erinnerungen Relevanz für einen breiteren Kontext, werden diese vom Hippocampus in den Neocortex übertragen.
Eine ähnliche Herangehensweise liegt Bi-level Continual Learning zugrunde, denn auch hier werden Informationen zu unterschiedlichen Zwecken in zwei voneinander getrennten Modellen gespeichert. Das dem Hippocampus entsprechende Modell verteilt seine Gewichte basierend auf dem Wissen des Neocortex-Äquivalents und gibt dabei Erkenntnisse für zukünftige Trainingseinheiten zurück. Ziel ist es, einerseits auf einen breit angelegten Wissensspeicher zurückgreifen zu können, und andererseits zügig neue Aufgaben zu erlernen. Ganz so, wie es der Mensch tut.
So funktioniert Machine Learning mit dem Scanbot SDK
Die Deep-Learning-Engine von Scanbot ist auf das Erkennen viele verschiedener Dokumentenarten ausgelegt, damit eine verlässliche Datenextraktion erfolgen kann. Dafür müssen wir die Auswirkungen von catastrophic interference möglichst gering halten.
Unser Ansatz lautet Modularisierung: Statt die Engine alle Aufgaben im Alleingang ausführen zu lassen, die mit dem Erkennen von Dokumenten und der Datenextraktion zusammenhängen, verteilen wir sie auf mehrere kleinere Module. So können wir sie einzeln trainieren und spezielle Anpassungen an ihnen vornehmen, ohne dass sich das auf andere auswirkt.
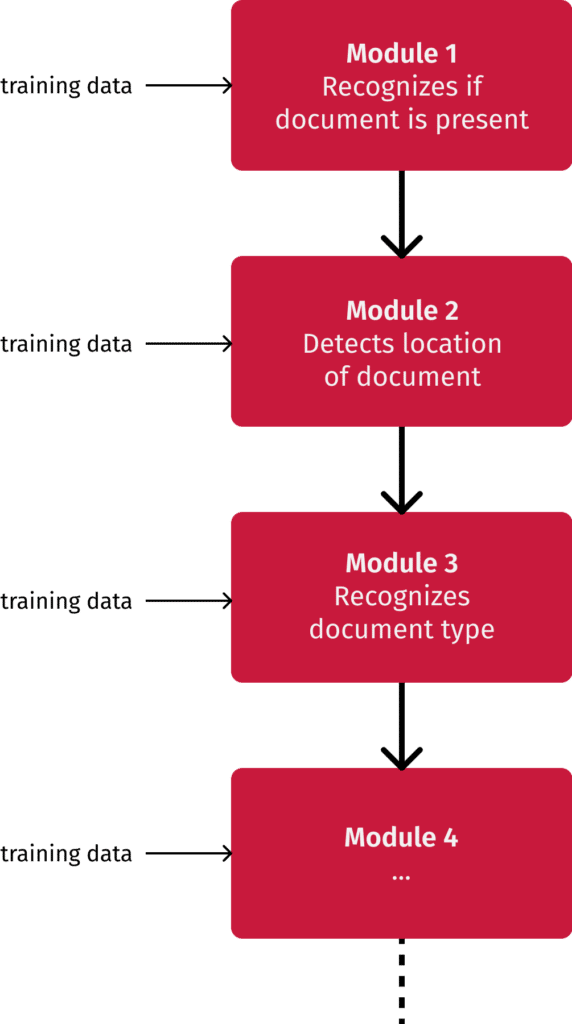
Unsere vorherige Herangehensweise mit einem einzigen, großen Modell hatte lange Trainingszeiten von bis zu 8 Stunden pro Aufgabe zur Folge. Zudem kam die Engine durcheinander, wenn wir sie auf mehrere Dokumententypen trainierten, die sich sehr ähnlich waren. Mittels Modularisierung konnten wir diesen Problemen entgegenwirken, sodass eine einzelne Trainingseinheit nun nur noch 15 bis 120 Minuten in Anspruch nimmt und Verwechslungen reduziert werden konnten.
Wir haben es uns zum Ziel gemacht, unsere Engine zukünftig innerhalb von nur 3 Arbeitstagen erfolgreich auf einen neuen Dokumententyp trainieren zu können. Derzeit dauert das noch 2 bis 3 Wochen. Unsere Entwickler:innen geben alles dafür, dass sich das bald ändert, sodass wir alle Arten von Dokumenten abdecken, die Sie für Ihren Use Case benötigen. Wenn Sie mehr über das Data Capture SDKvon Scanbot erfahren möchten, kontaktieren Sie unsere Lösungsexpert:innen. Wir freuen uns darauf, unsere Engine auf Ihre Anforderungen zu trainieren, um Ihnen eine automatisierte Verarbeitung von komplexen Dokumenten zu ermöglichen. Let’s talk.